
Python利用深度优先搜索解数独程序的实现
本文附带项目Github仓库地址,随手star是个好习惯:
https://github.com/SergioChan/Python-Sudoku
前两天吃饭的时候听到旁边一桌估计是搜狐或者网易的程序猿在说要是新员工给我面试我就让他写个解数独的Python程序,他二十分钟就能连伪代码加实现一起搞定……我上网一看,解数独这个问题确实挺有趣的,主要是纯凭自己好像很偶尔才能解出一个数独来的样子,于是根据以前学的数据结构的基础和最近新学的Python功底,小试牛刀一下,就使用最简单的回溯方法来实现,我知道百度上其实挺多的,但是说实话那些乱七八糟的代码我也看不太懂,自己想自己写可能思路属于自己,会比较清晰吧。回溯搜索是深度优先搜索(DFS)的一种
对于某一个搜索树来说(搜索树是起记录路径和状态判断的作用),回溯和DFS,其主要的区别是,回溯法在求解过程中不保留完整的树结构,而深度优先搜索则记下完整的搜索树。
“芬兰数学家因卡拉,花费3个月时间设计出的世界上迄今难度最大的数独游戏,而且它只有一个答案。因卡拉说只有思考能力最快、头脑最聪明的人才能破解这个游戏。”这是英国《每日邮报》2012年6月30日的一篇报道。我接下来就会用这个数独来做示范,说明利用回溯解决这个问题的思路。
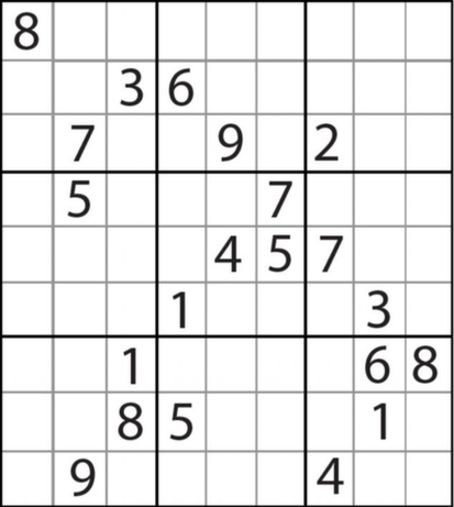
解决数独的关键思想在于找到一个入口点,将解决树一层层撸下去,遇到无法继续生长下去的结点,就往上回溯,回溯之后从上一个结点的其他分支继续往下走,如果没有其他分支则继续往上回溯。
先将整个数独矩阵用二维数组存储:
problem = \ |
之后,在解的过程中,由于需要回溯,所以需要把经历过的节点记录下来,我并不知道有没有更好的处理方式,这里用的是栈的存储方式,将经历过的节点存储在solutionStack中,当需要回溯的时候,直接pop掉栈顶的solution,如果解完了,则栈顶就是最后的结果。当经历了一个新的分支,在矩阵中添加了一个新的值,则随之产生一个新的节点,压入栈中。
然后,每个节点的数据并不只限于当前的矩阵状态(我其实觉得这里换成一个节点的数据结构会比较好),还包括矩阵中每个点可能的分支,这个栈的压入和弹出是和solutionStack同步的。每当进入新的分支,都需要将这个节点的可能解中修改过的值去掉,这样在往下走并且回溯的时候,就可以回到这个节点的修改后的可能解情况,即刚刚走过的那个分支不会再重复走一遍。
主方法:
import time |
在开始循环之前,需要先获得初始状态的分支情况,因此独立的获取分支状况的方法如下:
def get_solution_array(problem): |
这里需要说一点,其实每次压栈的时候节点状态做局部更新就好了,这样会减少很大的计算量,这个优化会在之后进行。每次到了新节点都要寻找下一个修改的坐标,这里就寻找的是下一个可能解最少的元素作为下一个节点。
def get_first_possible_item(solution_array): |
补充一个判断是否需要回溯的方法:
def check_if_need_to_back(solutionNow,solutionArray): |
最后的输出:
[8, 1, 2, 7, 5, 3, 6, 4, 9] |
这里的一处细节是最后的运行时间是5.2055秒,这相对于其他人的实现方式慢了一些,我在get_solution_array中用来判断所获取的值是否在可能解的候选数组中的时候,之前用的是list.count(object)这个方法来判断,后来改成了in,事实证明如果使用.count的话总消耗大概在5.6秒左右,会比in多出0.4S。
恩。我改成局部更新数据了。新的获取可能解的方法:
def get_resolution_array_new(solutionArray,x,y,value): |
将主方法中38行代码改为:
solutionArray_tmp = copy.deepcopy(solutionArray) |
最后的结果如下……也不咋地嘛,只是快了0.4S……看来还有优化空间吧
[8, 1, 2, 7, 5, 3, 6, 4, 9] |
–>继续补充
早上起来想了想又监控了一下,发现最主要耗时的还是在走的分支数量上,如果按照每次往下都默认走最左边的分支,那么前进会操作12000多次,回溯也差不多这个数,这是导致时间增大的主要原因。我没有想好如何在几个分支要选择的时候选择最优分支……毕竟我觉得去选择最优分支也要消耗时间,考虑太多意义不大……于是我就简单的尝试了一下随机分支,当程序运行到一个节点需要继续往下分支的时候随机选择一个分支,随机就用的最简单的随机方法,结果效果惊人,最快的时候可以达到:
[8, 1, 2, 7, 5, 3, 6, 4, 9] |
当然由于采用了随机,所以时间并不稳定……在这种最优解的情况下只要前进5000次就能到达最终解。如何有一个稳定的最优算法也许永远会是个谜吧。
随机选择分支的代码如下:
next_item_array = solutionArray[next_item_cord['x']][next_item_cord['y']] |
–>又找出一个问题
在获取下一个最优节点的过程中,没有算上当前矩阵中的那个值,所以会导致一个点连续的用了两次,最后可能还要回溯,所以修改了一下代码后,效率继续提升:
def get_first_possible_item(self, solution_array, solutionNow = None): |
在这种情况下,如果不用随机选择节点的方法,前进的次数稳定在9100次左右,比之前少了3000次左右,因此速度也提升到了3.6S,比4.8S提升了1.2S左右,变化显著。然后,尝试了一下随机选择节点的方式,目前计算出的最优解精确的是4142次,耗时1.6262S。另外,如何选择最优节点,继续减少解的路径应该是最终的优化办法了吧……
[8, 1, 2, 7, 5, 3, 6, 4, 9] |